Elm və texnologiyanın eksponensial tempdə inkifaş etdiyi bu dövrdə cəmiyyətimiz tarixin ən dinamik əmək bazarı ilə qarşı-qarşıyadır. Yeni ixtisas sahələrinin yaranması, mövcüd ixtisasların çeşidlənməsi və bazar tələblərinin daim dəyişməsi gənc nəsli saysız-hesabsız seçimlə, nəticə etibarilə, qərarsızlıqla üz-üzə qoyur.
Bu məqaləni yazmaqdaki məqsədlərimdən biri data elmi ilə bağlı bildiklərimi paylaşmaq, müstəqil araşdırma nümunəsi təqdim etməkdir. Bir digər məqsəd isə ölkədəki əmək bazarını tədqiq etmək, işaxtaran gənclərin ağlındaki bir sıra suallara dəqiq, data əsaslı cavablar tapmaqdır.
Məqalə boyu məlumatları necə topladığımı, necə təmizlədiyimi, necə vizuallaşdırdığımı və analiz etdiyimi sizlərlə bölüşəcəm.
Araşdırılan suallar
Cari əmək bazarında informasiya və rabitə texnologiyaları sahəsi üzrə:
- Ən çox hansı pozisiyalara tələb var?
- Ali təhsilə nə qədər əhəmiyyət verilir?
- Ən çox hansı bilik və bacarıqlar tələb olunur?
- Xarici dil bilikləri nə qədər zəruridir?
1. Data Collection
1.1 Data Sources
Düşünürəm ki, əmək bazırını ən yaxşı əks etdirən vasitələrdən biri iş elanları saytlarıdır. Məhz bu saytlar bizə əmək bazarında ən çox hansı pozisiyalara, həmçinin, hansı biliklərə tələbin olduğunu açıq-aşkar göstərir. Sözsüz ki, sadalanan bütün tələblərin həqiqətən də həmişə zəruri olduğuna zəmanat vermək olmaz. Lakin kifayət qədər data toplaya bilsək bazarın cari trendləri ilə bağlı müəyyən təsəvvür formalaşdıra bilərik.
Buna görə də araşdırmamızın birinci mərhələsi ölkədə etibarlı hesab olunan online iş axtarma platformalarının birindən son 1 ildə dərc olunmuş iş elanlarını bir dataset-ə yığmaq olacaq. Bu proses xüsusi alqoritmlər vasitəsi ilə avtomatikləşdirilir və Data Scraping adlanır.
Dataset-imiz Busy.az saytında son 1 ildə informasiya və rabitə texnologiyaları sahəsi üzrə dərc olunmuş vakansiyaların başlıqlarını, tələblərini və dərc olunma tarixlərini əhatə edəcək.
Qeyd: məlumatların araşdırma məqsədli toplanması üçün sayt rəhbərliyindən müvafiq razılıq alınıb. Siz də öz araşdırmalarınızda data etikası prinsiplərinə əməl etdiyinizdən əmin olun.
1.2 Python ilə Data Scraping
Python vasitəsi ilə data mənbəyimizə avtomatik veb sorğular göndərərək mövcud məlumatı JSON faylına yığacaq bir proqram tərtib etdim:
elanlar = open("elanlar_siyahisi.txt", "r").readlines()
for elan in elanlar:
response = requests.get(elan.strip())
if response.status_code == 200:
print("Uğurlu sorğu")
soup = BeautifulSoup(response.text, 'html.parser')
basliq = soup.find(class_='header details').find("h1").get_text(strip=True)
telebler = soup.find(class_="single-page-section").get_text()
tarix = soup.find(class_="icon-material-outline-date-range").find_next_sibling("h5").text
elan_data = {
"Title": basliq,
"Requirements": telebler,
"Date": tarix
}
with open('dataset.json', 'a', encoding='utf-8') as output:
output.write(json.dumps(elan_data, ensure_ascii=False, indent=4))
output.write(',\n')
time.sleep(2)
else:
print(f"Uğursuz sorğu: {response.status_code}")
Nəticədə 5995 sətirdən ibarət aşağıdaki JSON faylını əldə edirik:

Gördüyünüz kimi elanlar müxtəlif dillərdə yazılıb, "Requirements" hissəsi isə bizə lazım olmayan məlumatlarla doludur. Növbəti addımda məqsədimiz bu problemləri həll etmək olacaq.
2. Data Cleansing and Preparation
Əlimizdəki dataset-i analizə hazır vəziyyətə gətirmək üçün çoxlu sayda əlavə prosedurdan keçirtdim. Lakin məqalənin çox uzanmaması üçün burada faydalı olacağını düşündüyüm 2 əsas məsələyə toxunacam:
- Eyni bir pozisiya adının müxtəlif dillərdə və formalarda yazıldığı halları təyin edib qruplaşdırmaq (Clustering).
- "Requirements" (Tələblər) bölməsindəki uzun mətnlərdən konkret olaraq tələb olunan bacarıqların siyahısını çıxarmaq.
2.1 Məlumatın Ortaq Dilə Gətirilməsi
Əlimizdəki datanı düzgün qruplaşdıra bilmək üçün onu vahid bir dilə gətirməliyik. Bunun üçün Python-da googletrans kitabxanasından istifadə edə bilərik. Bu kitabxana bizə Google-un tərcümə xidmətindən Python mühitində istifadə etməyə imkan verir.
translator = Translator()
def translate_text(text, target_language='en'):
try:
return translator.translate(text, dest=target_language).text
except Exception as e:
print(f"xəta: {e}")
return text
# Mövcud dataset-i aç
with open('dataset.json', 'r', encoding='utf-8') as file:
data = json.load(file)
for item in data:
if 'Title' in item:
item['Title'] = translate_text(item['Title'])
print(item['Title'])
# Tərcümə olunmuş başlıqları yeni dataset-ə yaz
with open('translated_dataset.json', 'w', encoding='utf-8') as file:
json.dump(data, file, ensure_ascii=False, indent=4)
2.2 K-means Clustering (Qruplaşdırma)
İndi isə bizə lazımdır ki, dataset-imizdə eyni mənaya gələn lakin fərqli formada yazılmış pozisiya adlarını qruplaşdıraq. Məsələn, "Front-end developer" və "Developer (frontend)" başlığı ilə dərc olunmuş 2 fərqli vakansiyanı eyni bir qrupa salmalıyıq. Əks halda həmin pozisiya üçün neçə vakansiyanın olduğunu saya bilmərik.
Bunun üçün qruplaşdırma alqoritmlərindən biri olan K-means clustering alqoritmindən istifadə edəcəm. Bu alqoritm input olaraq x sayda n-ölçülü vektorları alır, və onları k sayda qruplara ayırır. Bu qruplaşdırmanı da vektorlar arasındaki məsafəyə əsasən aparır. Bu və digər qruplaşdırma metodları barəsində başqa bir məqalədə daha ətraflı yazacam.

Verilmiş nöqtələri 4 qrupa bölmək tələb olunur. K-means alqoritmi 6 iterasiyadan sonra qrupları təyin edir.
Bizim qruplaşdırmağa çalışdığımız data sözlərdən ibarətdir. Bu alqoritm isə vektorlarla işləyir. Ona görə də biz sözlərdən ibarət olan datanı vektorlarla ifadə etməliyik. Bunun üçün TF-IDF Vectorization üsulundan istifadə edəcəyik.
TF-IDF (Term Frequency-Inverse Document Frequency) Vectorization - Mətnlərin ədədi vektorlar olaraq ifadə edilməsi üçün nəzərdə tutulmuş bir üsuldur. Qısaca izah etsək, bu üsul mətndəki hər bir sözə bir ədədi qiymətin verilməsindən, daha sonra bu ədədlərdən vektorun qurulmasından ibarətdir. Bu ədədi qiymətlər isə həmin sözün verilmiş mətndə nə qədər çox təkrarlandığından asılıdır və sözün TF-IDF qiyməti adlanır.
Mətn tipli dataların TF-IDF Vectorization üsulu ilə vektorlaşdırılması və əldə olunan vektorların K-means clustering üsulu ilə qruplaşdırılmasına ən sadə nümunə kimi aşağıdaki proqrama nəzər yetirək:
# Nümunə dataset
data = {'title': ['front-end developer', 'developer (front-end)', 'backend developer', 'developer (backend)', 'junior frontend engineer']}
df = pd.DataFrame(data)
# Vectorization
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(df['title'])
# Clustering
k = 2 # Qrupların sayı
model = KMeans(n_clusters=k)
model.fit(X)
df['cluster'] = model.labels_
print(df)
Bu kod bizə aşağdaki nəticəni verir:
title cluster 0 front-end developer 1 1 developer (front-end) 1 2 backend developer 0 3 developer (backend) 0 4 junior frontend engineer 1
Gördüyünüz kimi front-end ilə bağlı olan elanlar 0 saylı, back-end ilə bağlı olan elanlar isə 1 saylı cluster-ə salınıb.
Bu qaydada əlimizdəki bütün datanı 24 qrupa böldüm. JSON formatında olan dataset-imizi CSV-yə çevirdim ki, onu Excel-də aça bilim. Excel-də isə qrupları manual olaraq bir neçə yoxlanışdan keçirtdim, zəruri dəyişiklikləri etdim və adlandırdım.
2.3 Tələb olunan bacarıqların ayrışdırılması
İndi isə bizə lazımdır ki, hər bir elan üçün tələb olunan texniki bacarıqların konkret siyahısını çıxaraq. Bu məlumat bizə 'Requirements' sütununda verilib. Bizə lazımdır ki, həmin sütundan bizə lazım olmayan mətni təmizləyək və oradan lazımi açar sözləri yeni yaratdığımız 'Skills' sütununa yazaq. Aşağıdaki nümunədəki kimi:

Bunun üçün Python-da aşağıdaki proqramı tərtib etdim:
# Axtarılan bacarıqların siyahısı (nümunə)
skills = ['python', 'java', 'sql', ...]
# 'Requirements' sütnununa tətbiq ediləcək funksiya
def extract_skills(requirements):
requirementsCleaned = re.sub(r'[&,\n;]()', ' ', requirements.lower())
matched_skills = [skill for skill in skills if skill.lower() in requirementsCleaned]
return ', '.join(matched_skills)
df = pd.read_excel('dataset.xlsx')
# 'Requirements' sütnununa extract_skills funksiyasını tətbiq et
# və nətincəni 'Skills' sütnununa yaz
df['skills'] = df['Requirements'].apply(extract_skills)
df.to_excel('dataset_updated.xlsx')
'Skills' çoxluğu fərqli peşələr üzrə mühim olan 186 müxtəlif texniki bacarığın adını əhatə edir. Qeyd edim ki, məlumatın daha düzgün toplanması üçün bəzi abreviatura və akronimlərin həm qısa, həm də geniş yazılışları bura daxildir.
Əsas cədvəlimizdə 'Skills' sütununu yuxarıdaki qaydada yaratdıqdan sonra yeni cədvəl yaratdım. Bu yeni cədvəl araşdırdığımız 186 texniki bacarığın hər birinin müxtəlif peşələr üzrə neçə dəfə təkrarlandığını bizə göstərəcək. Başqa bir sözlə, 'Skills' sütunundaki məlumatları ayrı bir cədvəldə ümumiləşdirəcəyik. Bu proses data aggregation adlanır.
Əsas cədvəlimizdəki məlumatları sayıb yeni cədvələ daxil etmək üçün bu formulu yazdım:
=COUNTIFS(elanlar[Cluster]; B$1; elanlar[skills]; "*"&$A2&"*" )
Nəticədə hər peşə üçün hər bacarığın neçə dəfə qeyd olunduğunu gösətərən aşağıdaki cədvəli əldə edirik:

Cədvəli əvvəlcə transpose etdim ki, peşə adları bir sətir üzərində yox, bir sütun üzərində olsun və Power BI-da bu sütunu əsas cədvəlimizlə əlaqələndirə bilim. Daha sonra bacarıq adları ilə bağlı olan sütunları seçib unpivot etdim. Əldə etdiyimiz cədvəli bir neçə əlavə yoxlanışdan keçirtdim. Nəticədə cədvəlimiz artıq vizuallaşdırılmağa hazırdır.
3. Data visualisation
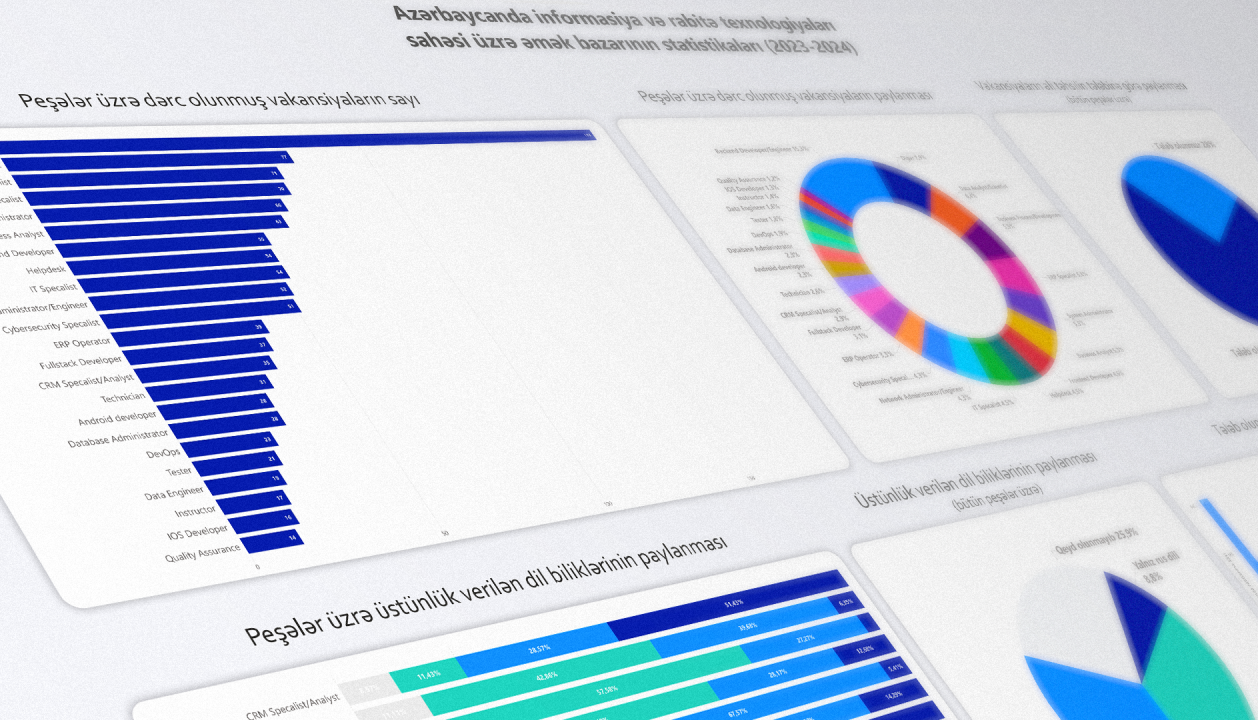
Power BI vasitəsi ilə aşağıdaki interaktiv dashboard-u yaratdım:

4. Məlumatların analizi
Məqalənin əvvəlində qoyduğum suallara artıq cavab verə bilərik.
4.1 Descriptive & Diagnostic Analysis
1) Ən çox hansı pozisiyalara tələb var?


1a. Qrafiklərdən göründüyü kimi, back-end developerlər son 1 ildə IT sahəsində ən çox axtarılan işçilərdir və bütün vakansiyaların 15.3%-ni təşkil edirlər.
Dünyada rəqəmsallaşma trendinin davam etməsi ilə birgə şirkətlər öz xidmətlərini və daxili proseslərini rəqəmsallaşdırma istiqamətində çalışır. Bu onlara həm əməliyyat xərclərini azaltmağa, həm də xidmətlərini daha əlçatan etməyə kömək edir. Bu rəqəmsallaşmanın da böyük bir hissəsi lazımi rəqəmsal məhsulların yaradılmasından ibarətdir, hansı ki, bu işin də əsas hissəsi back-end developer-lərin öhdəliyidir.
1b. İkinci yerdə vakansiyaların 6.4%-ni təşkil edən data analyst və data scientist-lər gəlir.
Yerli şirkətlərdə Data Əsaslı İdarəetmə anlayışının son bir neçə ildə populyarlaşması ilə əlaqədər olaraq data sahəsində də mütəxəssislərə tələb çoxdur. Xidmət və məhsulların rəqəmsallaşması ona gətirib çıxarıb ki, artıq potensial müştərilərin atdığı hər addım barəsində statistik məlumat yığmaq mümkündür. Belə halda da bu statistik məlumatların imkanlarını üzə çıxaracaq mütəxəssislərə, yəni, data analyst-lərə və scientist-lərə ehtiyac doğur.
1c. Üçüncü yerdə Business Process/Development Specialist-lər yer alır.
Tarix boyu təklif etdiyi xidmət, məhsul və apardığı strategiya bazarın dəyişkənliyi ilə uyğunlaşa bilmədiyinə görə uğursuzluğa çevrilmiş saysız-hesabsız şirkət nümunəsi olub. İndiki bazar mühitinin ən dəyişkən olduğu zəmanədir, bu mühitdə yaranan fürsətləri görəcək, uyğun strategiyalar və layihələr quracaq mütəxəssislərə ehtiyac da hər zamankindən daha çoxdur.
2) Ali təhsilə nə qədər əhəmiyyət verilir?

Bütün vakansiyaların 72%-i namizədlərdən ali təhsilin tələb olunduğunu vurğulayıb. Vakansiyalarında ən çox ali təhsil tələb edən peşələr business analyst (92.1%) və cybersecurity specalist-lərdir (92.2%). Ən az ali təhsil tələb edən peşələr isə IOS developer-lər (37,5%) və technician-lardır (38,7%).
3) Ən çox hansı bilik və bacarıqlar tələb olunur?

Ən çox tələb olunan 3 texniki bacarıq ardıcıl olaraq SQL (vakansiyaların 68%-i), Microsoft Excel (46%) və Git-dir (40%). Aydındır ki, bu bacarıqlar çox yönlü istifadə imkanlarına malik olduqları üçün müxtəlif peşələrə aid vakansiyalar üçün tələb oluna bilir.
Proqramlaşdırma dilləri arasında ən çox tələb olunan dillər ardıcıl olaraq SQL, Python və C#-dır. 2023-cü ildə beynəlxalq statistikada proqramlaşdırma dilləri arasında populyarlıq üzrə 1-ci olan JavaScript bu qrafikdə proqramlaşdırma dilləri arasından 5-ci yerdədir.
JavaScript framework-ləri arasında adı ən çox çəkilənlər ardıcıl olaraq React (106 elanda rast gəlinir), Angular (56), Express (52) və Vue-dir (40).
Verilənlər bazasının idarəetmə sistemləri arasında isə ən çox tələb olunanlar ardıcıl olaraq Oracle (210 elanda rast gəlinir), PostgreSQL (180) və MySQL-dir (130). Qeyd edim ki, burada birinci yerdə olan Oracle, beynəlxalq statistikada populyarlıq üzrə 9-cu yerdədir.
4) Xarici dil bilikləri nə qədər zəruridir?

Qrafikə nəzər yetirdikdə görürük ki, ümumilikdə bütün elanların 74.1%-i ən azı bir xarici dil tələb edir. İngilis dilinin cəmi 65.3% elanda, rus dilinin isə 41.8% elanda tələb (və ya arzuolunan) olduğu qeyd edilib.

Araşdırılan peşələr arasında ən az xarici dil tələb edən ERP operatorlar (38.7% elan ən az 1 xarici dil tələb edir) və technician-lardır (38.4%). Qeyd edim ki, technician peşəsi eyni zamanada ali təhsilin də ən az tələb olunduğu 2-ci peşədir.
Ən çox xarici dil tələb edən peşə isə CRM specalist/analyst-dir (91.43% elan ən az 1 xarici dil tələb edir). Bu peşə eyni zamanda rus dilinin ən çox tələb olunduğu peşədir (51.4% elan xarici dil olaraq yalnız rus dili tələb edir). Bunun səbəbi CRM specalist/analyst-lər üçün olan bəzi elanların müştərilərlə birbaşa əlaqədə olmaq kimi tələblərinin də olmasıdır. İkinci yerdə isə business analyst-lərdir, hansı ki, ən çox ali təhsil tələb edən peşələr arasında birincidir.
4.2 Prescriptive Analysis
Hamımız back-end developer olaq?
Təbii ki, xeyr. Əvvəla onu aydınlaşdırmaq lazımdır ki, bir peşəyə tələbin çox olması, ora yönəldikdə iş tapma ehtimalınızın daha çox olduğu mənasına gəlmir. Bu araşdırma işin tələblər aspektinə işıq saçsa da, bazarda bu peşələr üzrə olan rəqabət, yeni kadrların yetişdirilməsi üçün mövcud şərait və əmək bazarının digər xüsusi şərtləri barədə bir fikir deyə bilmərik. Buna görə də sırf vakansiya sayı çox olduğu üçün bir peşəyə yönəlmək yaxşı fikir deyil.
Ali təhsil
Statistika onu göstərir ki, ali təhsilli olmaq sizə bütün müsabiqələrin 72%-ində üstünlük verəcək (əslində qalan 28%-ində də üstünlük verəcək, lakin nisbətən daha az əhəmiyyət daşıyaraq). Bazarda tələb olunan texniki bacarıqlarla universitetdə sizə tədris olunan bacarıqlar arasındaki fərqi özünüz müşahidə edərək təhsil aldığınız müddətdə özünüzü necə təkminləşdirə biləcəyinizi müəyyənləşdirə bilərsiniz.
Xarici dil
Statistikaya əsasən, bütün vakansiyaların 74.1%-i ən az bir xarici dil tələb edir. Bu ədəd ali təhsil tələb edən vakansiyaların sayından da çoxdur (72%). Nəticə etibarı ilə, xarici dil bilmək sizə həm iş tapmaqda, həm də texniki bacarıqlarınızı xarici resurslarla təkminləşdirməyə kömək olacaq.
Müəllif: Nicat Zakirov, Data Analitika, BDU-nun Kompüter Elmləri ixtisasının məzunu



